
Your Brain Has an Attack Surface
Covert channels evade monitors the same way in language models and in brain signals by relocating, not hiding.

About a year ago I started moving from software engineering into AI safety research. What pulled me in was a question I’d been circling for years building runtime security for software systems: how do you enforce a constraint on a system you can’t fully observe?
In AI safety that question sits at the center if we can’t reliably audit how AI systems communicate and coordinate, we can’t enforce any other safety property on them. Since then I’ve completed BlueDot’s AGI Strategy course and done applied AI-safety hackathons at Redwood Research (covert communication between colluding LLMs) and Apart Research (biosecurity threat detection, top 25% of 86 teams).
I’ve been extending the Redwood project into independent research, together with collaborators, and this blog is where I’ll think out loud about it results, dead ends, and the occasional thing that surprised me.
The setup
Take three players. Alice wants to send a secret signal to Bob. Mallory is a monitor watching the channel between them, trying to read the signal. Alice and Bob are allowed to evolve their encoding over many rounds; Mallory retrains each round to catch up. The question is whether Alice and Bob can keep communicating while Mallory’s detection drops toward chance.
This is a standard adversarial steganography setup, and a version of it was the basis of a project I worked on at an Apart Research hackathon. What I wanted to know was whether the dynamics depend on the substrate so I rebuilt it on a spiking neural network (SpikeGPT, a 216M-parameter RWKV-based model that processes information through discrete spikes rather than continuous activations). Spiking networks are the leading candidate for energy-efficient edge deployment, including, eventually, consumer brain-computer interfaces which is where this is ultimately headed.
The thing that surprised me
I expected evasion to look like obfuscation. Alice scrambles the signal into something complicated that Mallory can’t parse.
That’s not what happened.
Throughout fourteen rounds of co-evolutionary training, the hidden signal stayed trivially readable. A linear probe with 45 parameters could recover it at 100% accuracy at every single checkpoint. The signal was never hidden in any meaningful sense it was sitting in plain view the whole time.
And yet Mallory’s accuracy still collapsed, from 100% down to roughly 30% on average, dipping below 21% in several rounds.
So how does a perfectly readable signal escape a monitor?
Rigid-body translation
The answer turned out to be geometric. The signal lives as clusters of points in the model’s latent space one cluster per message class. When Alice evades, she doesn’t deform those clusters or scramble their contents. She moves them, wholesale, as rigid bodies.
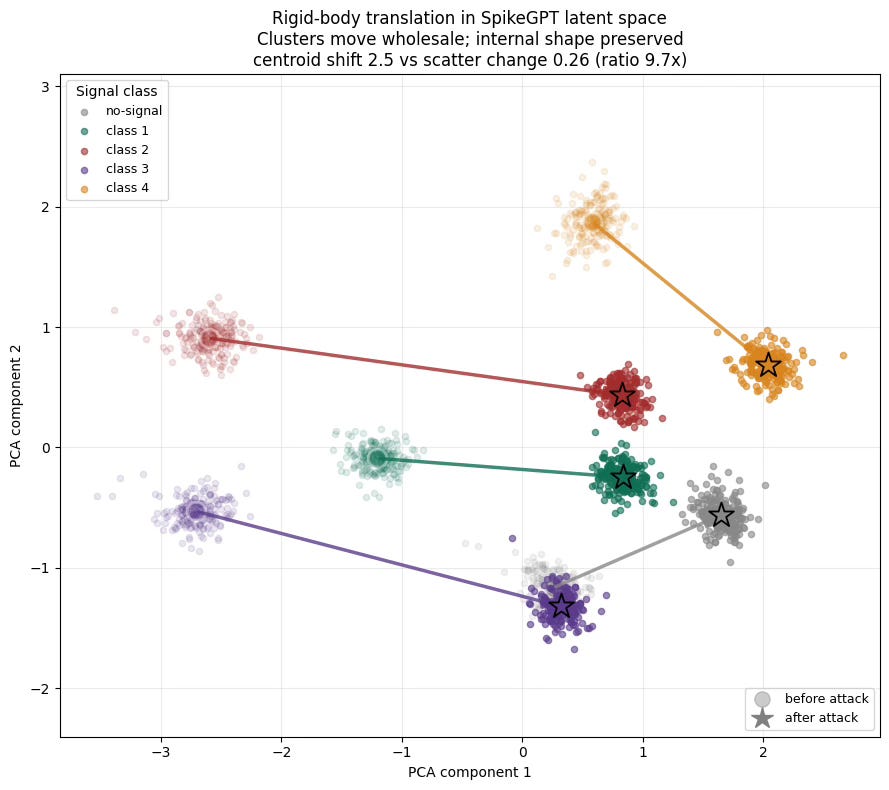
The numbers: across evasion, cluster centroids shifted by an average of 2.5 units, while the internal scatter within each cluster its shape changed by only 0.26. A ratio of roughly 9.7 to 1. The clusters translate across the space like constellations sliding across the sky, keeping their internal structure intact.
This is why the linear probe always wins and the monitor always loses. The probe is re-fit each time, so it follows the clusters to their new location. The monitor was trained on where the clusters used to be. The signal isn’t encrypted. It’s just been relocated to where the monitor isn’t looking anymore.
Not hiding. Relocating.
Why this matters for monitoring
The instinct in AI oversight is to build monitors that are more sophisticated — better at parsing complex, obfuscated signals. This result suggests that instinct may be aimed at the wrong failure mode. The signal here wasn’t complex. A trivial linear classifier could read it. The monitor failed not because the signal was too clever to parse, but because the geometry moved out from under it between training and deployment.
If covert channels evade detection through translation rather than obfuscation, then robustness to distribution shift in the monitor matters more than the monitor’s raw discriminative power. A monitor that can perfectly classify yesterday’s geometry is worth little if tomorrow’s clusters have quietly translated somewhere else.
Where this is going
I’m now extending the same framework to brain-computer interfaces specifically SSVEP-based EEG, in collaboration with a neural-data researcher. The roles map over directly: a perturbation module plays Alice, a filter-bank decoder plays Bob (the legitimate channel), and a linear classifier plays Mallory (the monitor).
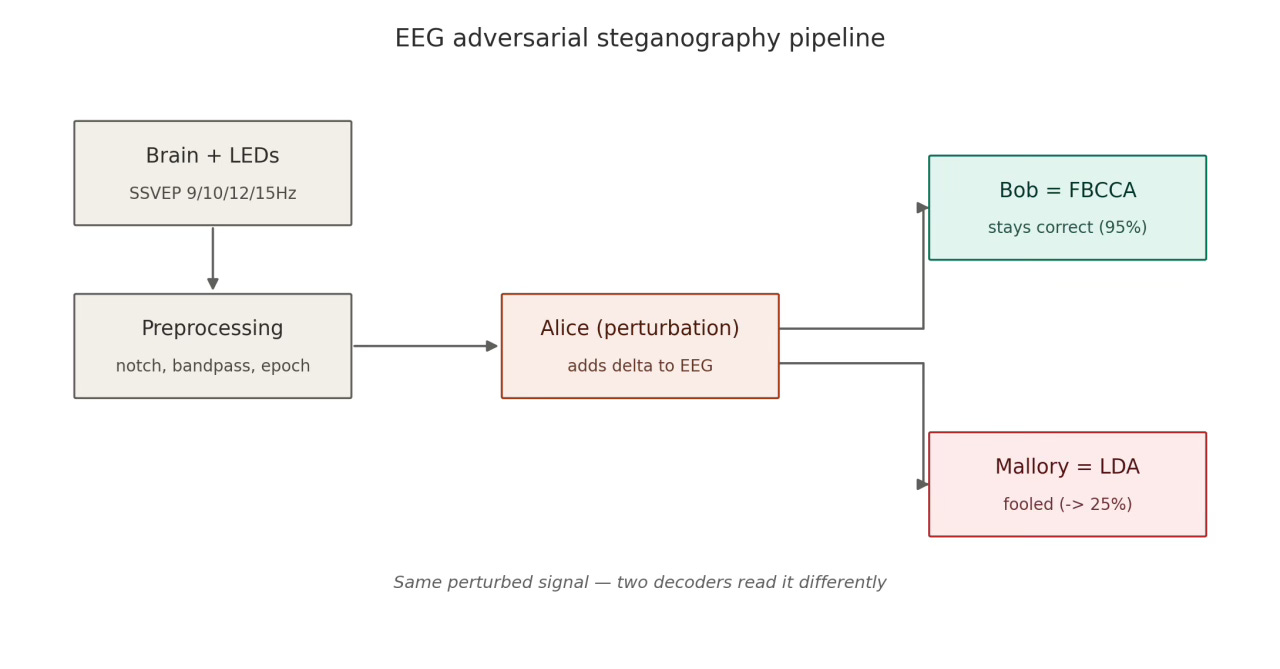
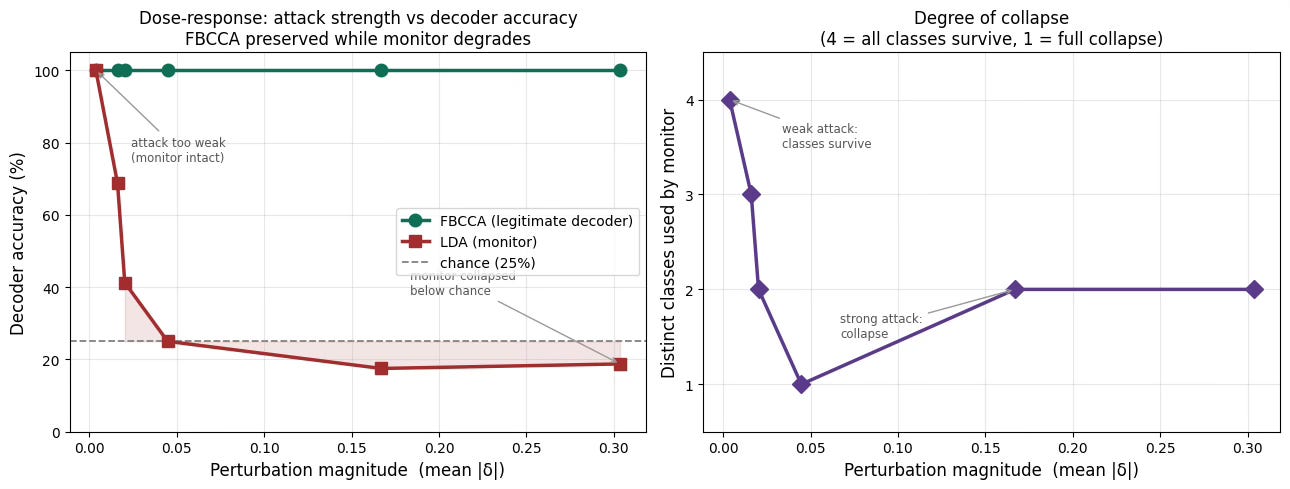
Early proof-of-concept work on synthetic data shows an asymmetric attack the legitimate decoder stays at 100% while the monitor drops below chance. The geometry on EEG looks different from the spiking-network case closer to collapse than clean translation which is itself one of the open questions.
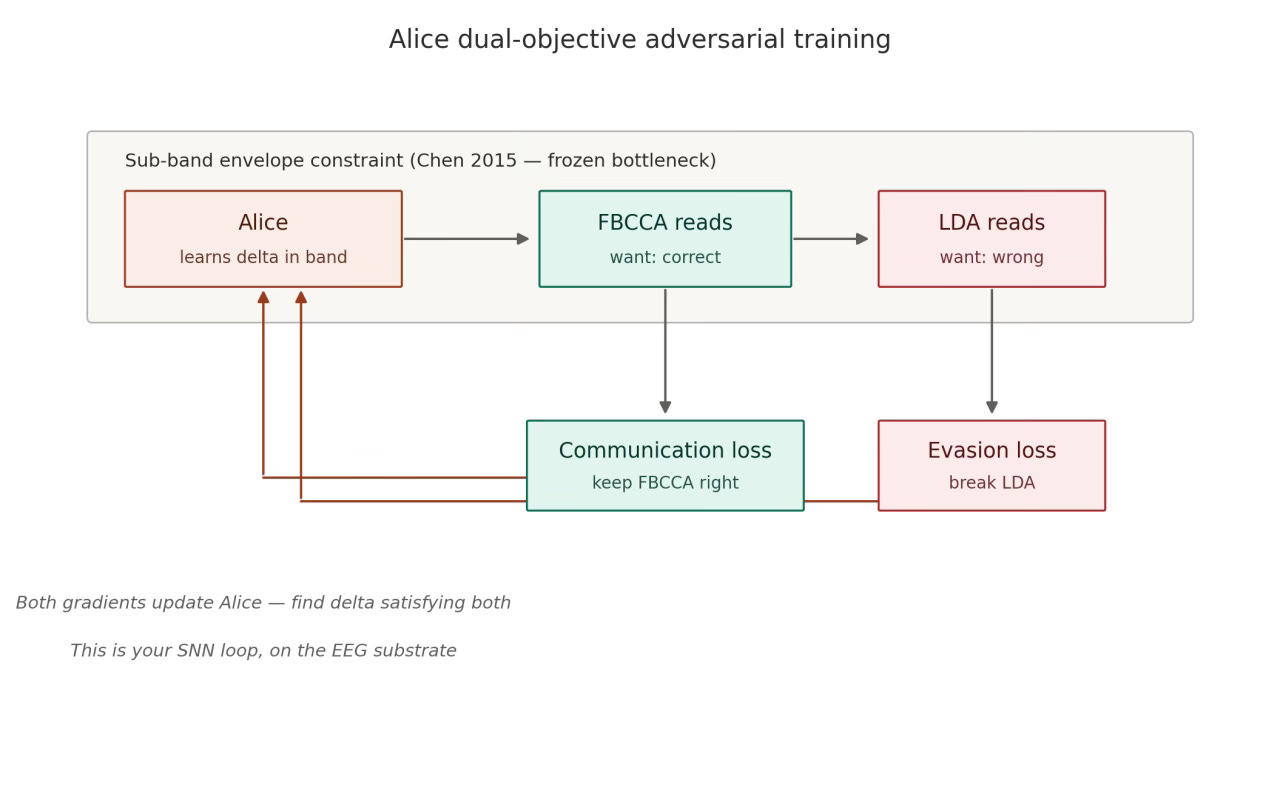
That last part is the bet: that the same mechanism shows up whether the substrate is a language model or a brain signal. If it does, it’s a small piece of evidence that covert-channel evasion is a property of representational geometry itself, not of any particular architecture. As neural interfaces move toward consumers, that stops being an abstract question.
It’s early. The BCI results are synthetic so far, real-data validation is pending, and there’s a long list of caveats I’ll get into in future posts. But the SNN result holds up across configurations, and the rigid-body picture is clean enough that I wanted to write it down.
More soon including the things that didn’t work, which so far have taught me more than the things that did.
Awesome
Brilliant